Playing Smash Bros. with Neural Networks
One of the coolest applications of machine learning to me is using it to learn to play video games. It’s what got me interested in reinforcement learning in the first place. There’s nothing quite like watching an algorithm slowly go from pressing random buttons, to having almost complete mastery of a game, to the point where it sometimes it’ll do things that surprise even you.
I’ve been spending some time on the side trying to train an agent to play Smash Bros. In this post, I’ll share what my approach was, and also highlight some of the prior work that’s been done here.
But Why Smash?
For the uninitiated, Super Smash Bros. is a fighting game series where two players attempt to knock each other off of a shared platform. Each character is equipped with a variety of moves to inflict damage (measured as a percentage from 0% to 999%) and send the opponent flying. The more damage a fighter, the harder they fly back.
Its large roster of iconic video game characters (where else can you watch Mario beat up Pacman?), alongside its easy to learn yet difficult to master gameplay, has made it one of Nintendo’s bestsellers. The latest game contains 82 different characters, all with their own moveset and properties.
For instance, Pikachu is a small, nimble fighter who has a variety of fast attacks, but can be easily launched from the stage even at low percentages due to its light body weight. Donkey Kong, on the other hand, is a powerful, heavy fighter with good horizontal recovery, but has a large hitbox and struggles to recover vertically.

Despite each fighter’s unique qualities, they all obey a common set of rules.
All characters have a set of standard attacks that can be executed on the ground (ground attacks) and in the air (aerial attacks) by pressing the “A” button and holding down a direction. If a direction is pressed at the same time the “A” button is pressed, the player can charge up a “smash” attack that deals heavy damage and sends the opponent flying. Each fighter is also equipped with four special moves that can be used by pressing the “B” button and a direction.
For defense, holding down the shield button causes a protective shield to appear around the character, which shrinks with more hits and time. While standard and special attacks can’t penetrate through the shield, this leaves the character open to being grabbed.
Aside from being fun to play, it’s also an interesting problem for AI! An agent capable of beating top players can’t just master the basic rules of the game, but also know how every character should fight against every other character. In one match up, the best strategy might be to keep the opponent away by shooting at them, then running away when they get too close. In another, it might be best to get up close and unleash a flurry of attacks, forcing the other player to make mistakes.
To best make these decisions, the agent has to take a lot of variables into account: the positions of each player, which state each fighter is in (shielding? recovering? charging up a smash attack?), unique characteristics of the fighter (weight, jump height), how damaged they are, etc. Even if an agent did get really good at all of this, it’d still have to master the psychological aspect of the game, trying to get inside its opponent’s head while avoiding the same from happening to it.
While there are 5 games in the Smash series, we’ll be focusing on Super Smash Bros. Melee, the game with the most active competitive scene. Because it’s so widely played, the community has made it really easy to get it up and running on a PC, which makes training way easier.
Prior Work
A couple people have already experimented with using deep learning to train an agent to play Melee. Here’s a selection of work I was able to dig up:
- “Beating the World’s Best at Super Smash Bros. Melee with Deep Reinforcement Learning” (2017), a paper by Vlad Firoiu, William F. Whitney, and Josh Tenenbaum,
- “Learning to Play Super Smash Bros. Melee with Delayed Actions” (2017), a paper by Yash Sharma and Eli Friedman,
- “At Human Speed: Deep Reinforcement Learning with Action Delay” (2018), a paper by Vlad Firoiu, Tina Ju, and Josh Tenenbaum,
- “Project Nabla” (2022), a blog post by Brian Chen, and
- “AI Learns to Play Super Smash Bros” (2022), a video by the Youtuber AI Spawn.
I’ve broken these down by technique below. I’ll be giving super oversimplified explanations of how each reinforcement learning algorithm works; if you want to learn more, this is one of the most intuitive sources I’ve found for beginners.
Behavior Cloning
At the most basic, we have behavior cloning. These approaches take recordings of real players and train a network to replicate them.
The dataset will typically contain the state of the game as input, and a one hot encoded vector corresponding to the correct action as the output. Once the network’s trained, you pass data from the game to the network, and take the maximum value of the network.
- Project Nabla pretrains a network with scalar features to output one hot encoded actions. The network uses a recurrent GRU layers to take past frames into account.
- The AI Spawn video used a collection of publically available replays and trained an MLP on it.
Pros:
- Easy to understand and implement.
Cons:
- Doesn’t generalize well to unseen game states.
- You need an expert to record a bunch of games for you.
Deep Q Networks (DQNs)
Next, we have Deep Q Networks. This is the first algorithm where the AI learns by actually playing the game. Because there no longer is a “right answer” for each game state, we have to define a reward function for the game, like +1 if you knock the other player off, and -1 if you get knocked off instead. With Deep Q Networks, you train a network to associate each state with the reward it thinks it’ll get in the next state, and so on. Eventually, you get to a point where you can accurately predict how much reward you’ll get at any given game state, which means like with behavior cloning, you can just choose the action that outputs the max value.
- Firouiu (2017) trained DQNs both against the in-game AI and through self play, finding that Q networks could easily exploit edge cases in the opponent. They used an MLP where each player’s position, velocity, action state, etc were passed.
- Sharma trained a DQN with a recurrent architecture against the in-game AI to allow it to use information seen in previous frames.
- AI Spawn trained a DQN against the in-game AI, also finding that Q networks tend to take advantage of bugs in the in-game AI.
Pros:
- The simulation doesn’t have to be super fast, since you’re allowed to use all data collected since the start of training.
- You basically have infinite data because the agent plays more games during training.
Cons:
- It can lead to unnatural behavior, because it’s trying to find the objectively best way to play the game, like a speedrunner.
Policy Gradient Algorithms
Finally, we have policy gradient algorithms. Like DQNs, these algorithms learn to play video games by playing them over and over again. Unlike DQNs, instead of trying to predict the value of each action, the model assigns them probabilties. Initially, you start out with pretty much the same probability of performing any action, but as the model plays the game, it increases the probability of performing highly rewarding actions while doing the opposite for actions that lead to low reward.
- Firouiu (2017) compared an Actor Critic approach against their DQN and found that it tended to perform more realistic behaviors, attacking and evading.
- Firouiu (2018) used a recurrent neural network to predict the next frame to deal with input delay.
- Project Nabla uses a more efficient Actor Critic variant (PPO) to finetune the model after doing behavior cloning.
Pros:
- Like with DQNs, you have basically unlimited data to train on.
- They tend to give you more “realistic” behavior.
- Generally, I’ve gotten better results with policy gradient algorithms over DQNs.
Cons:
- You need a really fast environment, since you have to throw out all of your old experience after one iteration of training.
My Approach
I decided to go with PPO, which is a pretty standard policy gradient algorithm. It looked like DQNs tended to exploit edge cases in the opponent too much during training, making the behavior less realistic.
For my feature space, I decided to go with a combination of scalar and visual features. As we’ve seen with the other papers, scalar features alone are actually pretty informative, and they allow you to get away with less intensive architectures. My rationale was that giving the agent visual features is more “natural”, since it wouldn’t have to memorize things like how close another player has to be for an attack to hit. I didn’t want to turn this into a computer vision task, though, so instead of pixels, I just displayed the hitboxes and hurtboxes.
Because I didn’t want to iterate on an expensive environment, I wrote a fast, simple, Smash-like fighting game in Bevy. In the game, you can move left and right, and you also get a jump. There are four kinds of attacks:
- A fast, light attack, similar to Smash’s jab attacks,
- A slow, heavy attack, similar to Smash’s smash attacks,
- A projectile with a fair bit of startup, and
- A grab attack that ignores shields.
Speaking of shielding, that’s also something you can do.
Aside from being much faster to run than simulating a Gamecube, being such a simple environment means it’s easier to spot and debug strange behavior. For instance, agents turning away from each other and firing projectiles off stage could indicate that I accidentally switched their positions.
I also wanted agents to generalize to high level play, so instead of having agents play against the in-game AI, I used self play. I used the same technique shown in Huggingface’s RL course. At any given time, I had one active agent that was learning to play against a stable of opponents. The pool of opponents initially consists of a copy of the agent from before training starts, and every couple hundred of steps, I copy the active agent to the pool. Aside from the network, each opponent also keeps track of its current ELO, which corresponds to its performance compared to every other agent.
To update ELO scores, I set up evaluation runs to periodically run during training. Once I hit a threshold of opponents, I use ELO to figure out which agent to replace, removing the worst performing agents over time. Thus, as the training process continues, I’d end up with a better and better set of opponents for my active agent to fight against. This reduces the chance of the agent overfitting against one type of strategy.
I should note now that I was running all of this on my laptop, which struggles to play Cyberpunk 2077 on medium settings. With all these moving parts, training got pretty slow. To speeed things up, I ported over a lot of the hot code to Rust. While running things in a compiled language immediately sped up the code a bit, the major speedup came from the ability to use all the cores on my machine. Python’s GIL means writing multithreaded code isn’t easy, but with Rust, I could just spin up as many threads as I needed, while still being able to read from shared memory.
With a couple nights of training, my agents were looking pretty good! They strategically shot projectiles from far away, then inched closer to the opponent to finish them off with a heavy attack.
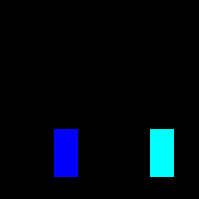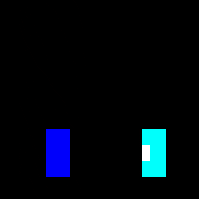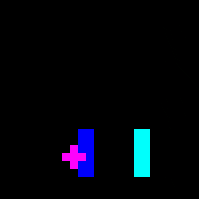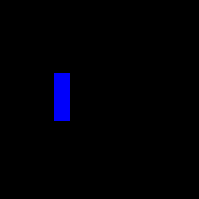
Once I was confident that everything was working, I set up training with libmelee. After training a couple nights, the agents generally seemed to understand that they were supposed to attack each other, and also that they shouldn’t jump off the stage.
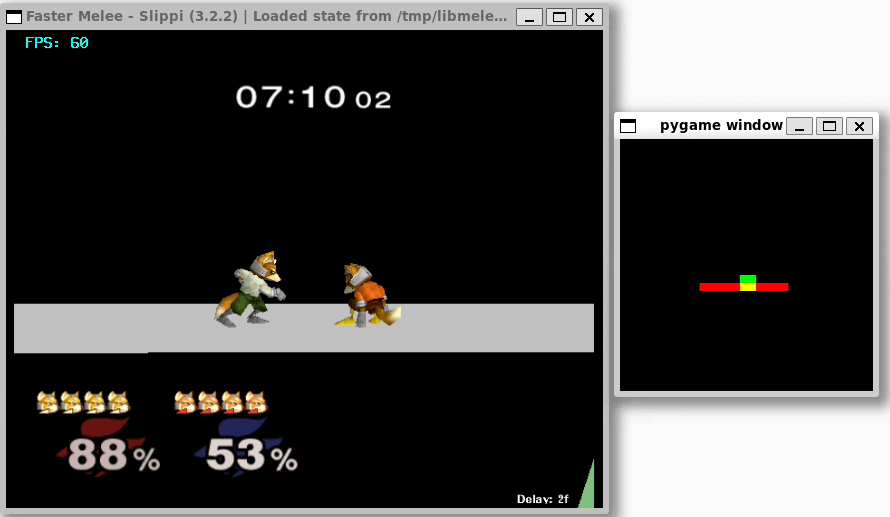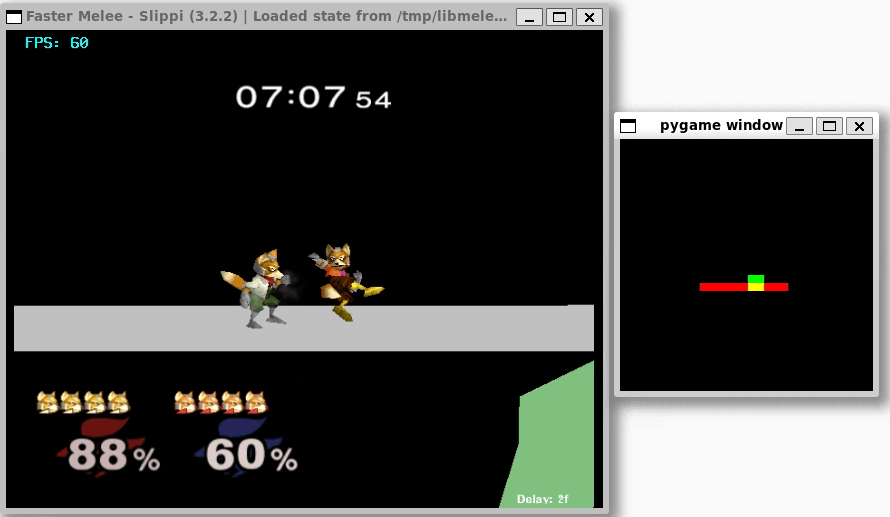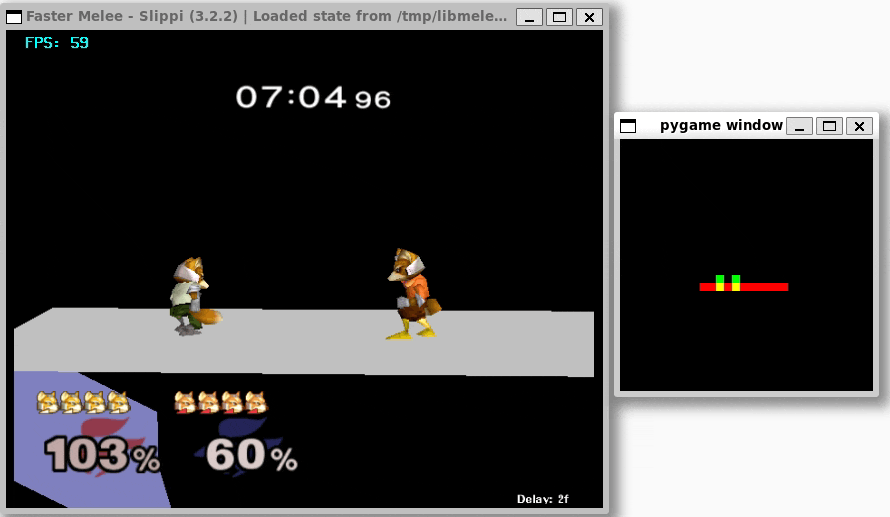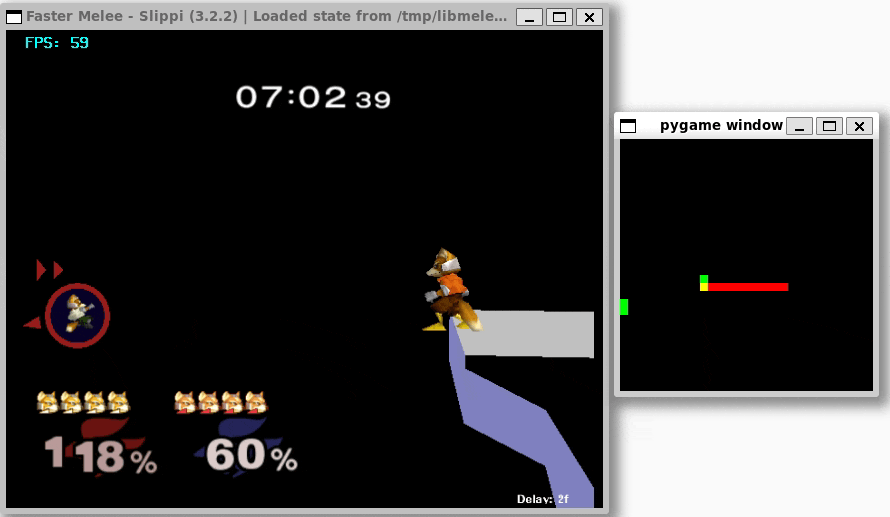
Conclusion
I’m pretty happy with what I have for now! The agents seem to know what they’re doing, and translating to a real environment feels relatively straightforward, even if it is slow.
If I let this train longer, I’d probably have an agent that could consistently beat me, although to be fair this isn’t hard to do.
With that said, I’m switching gears on this project. The real goal of this project has actually been to integrate retrieval into the process, giving agents the ability to use a giant dataset of experiences at during gameplay. This would reduce the need to memorize combos and strategies.
I’ll make a follow up post that details the state of that effort. In the meantime, you can see the current state of my code here: https://github.com/Boxxfish/smash-rl