How Baleen Works
As part of my Master’s thesis, I’ve been taking a look at Baleen, a multi-hop question answering (MHQA) system. The system builds on Khattab et. al’s previous work on late interaction based retrieval, most famously ColBERT. While it’s been cited in a number of blog posts, I haven’t found many resources actually going through how it works. In this blogpost, we’ll go through what Baleen is, how each component works, and how it’s trained.
I’ve also written a visualizer for Baleen here, where you can see how different queries are handled!
Task
The general family of tasks Baleen targets is multi-hop open domain reasoning. Open domain tasks require using a collection of documents to form a response. In other words, you can’t just have a language models “memorize” facts from a bunch of documents and ask it questions; the system has to act like it’s taking an open book test and retrieve pages needed to answer questions.
Multi-hop reasoning requires fetching information from a bunch of documents instead of just a single source. For example, let’s say you have the query “Was George Washington’s successor elected twice?“. The system would first have to look up information on George Washington to figure out who his successor was (John Adams), then look up information about John Adams see if they were elected twice.
The actual form of the answer is flexible; it could be the answer to a multiple choice question, a span of text from one of the retrieved documents, or just true/false.
The specific tasks Baleen addresses are question answering and claim verificiation. For question answering, the system retrieves a set of documents that allow it to answer a question. For claim verification, the system retrieves a set of documents that either prove or disprove a given claim, basically doing fact checking. The two datasets used are HotpotQA and HoVer, respectively. The authors primarily focus the latter, since they find that HotpotQA is too “easy” of a task — HotpotQA only requires at most 2 hops to answer a question, while HoVer requres 2-4.
Since we want our fact checking systems to be trustworthy and transparent, the quality of retrieved documents is very important. In fact, when evaluating a system on HoVer, whether or not the system produces correct answers is actually a secondary concern, at least when compared to how good the retrieved evidence is.
Each item in the dataset contains an unordered set of gold (passage, sentence) pairs, which model facts from passages.
Exact Match (EM) and F1 (a combination of precision and recall) are measured between the retrieved set and gold set of
facts. Obtaining a good passage EM and F1 (where the actual fact could be anywhere within a passage) is less challenging
than doing it at the sentence level. HoVer uses the Wikipedia 2017 Abstracts dataset, so each “passage” has around 1-4
sentences.
The System
Now that we understand what Baleen does, we’ll cover each of its components.
On each hop, the current query is run through a retriever to produce a set of candidate documents. Documents are then run through a 2-stage condenser to isolate the most relevant facts (e.g. sentences). These facts are added to the end of the query to form the next context, then the system performs the next hop. After a set number of hops, the query and context are sent to a reader, which determines whether or not the query is supported based on the provided context.
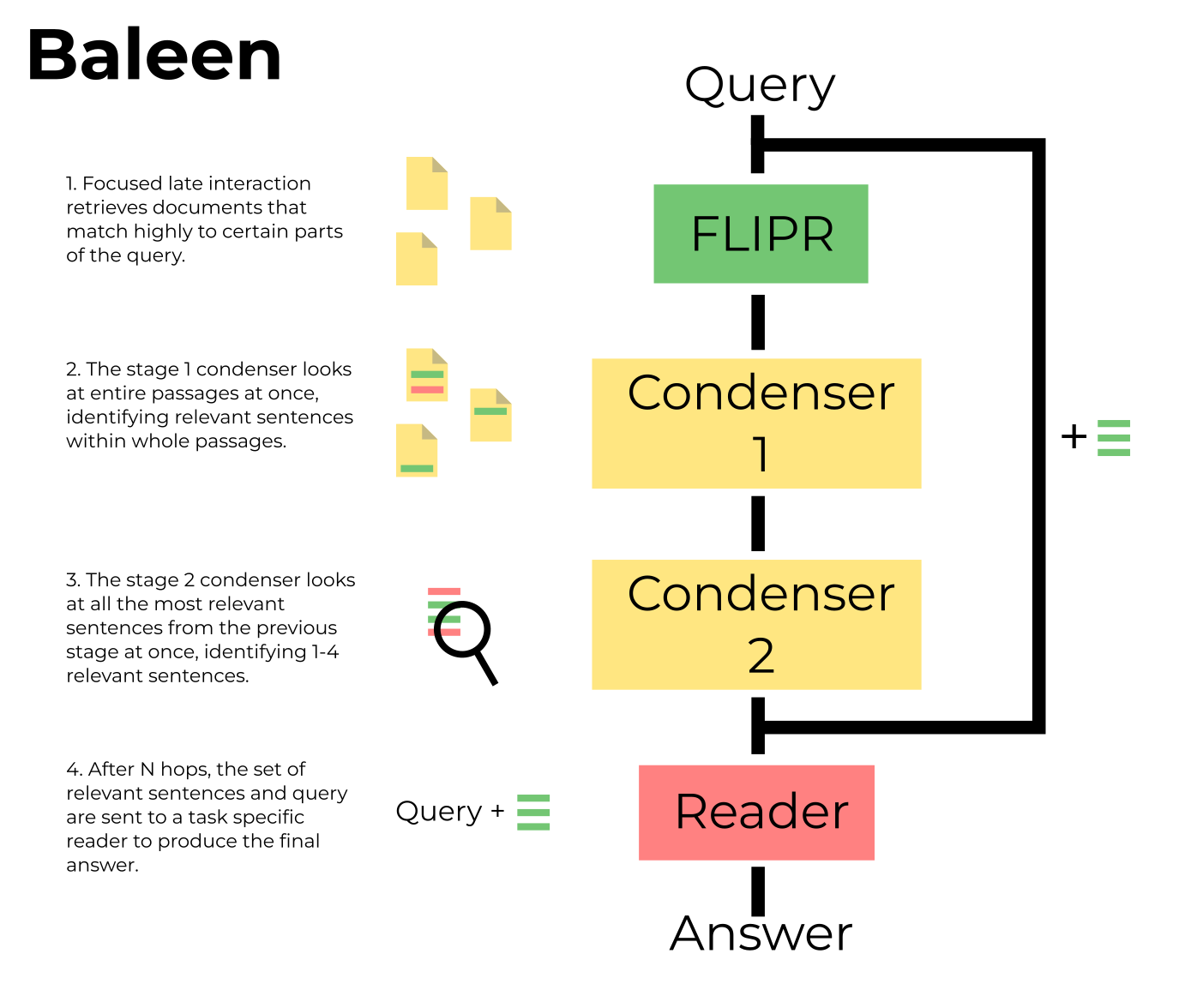
All components are implemented with Transformer-based language models.
Retriever
The retriever is very similar to ColBERT.
As a review, ColBERT is a neural retrieval model that contextualizes queries and documents, such that every query and
document token ends up being used for scoring. The score of a document is computed as the sum of the most similar
document embedding to each query embedding. ColBERT pads its queries with [MASK] tokens and includes this in the
scoring, so every query has the same number of query tokens. By default, 32 query tokens are used.
In the figure below, the cosine similarity between each query and document token has been computed. All scores indicated in green are the maximum similarity score for each query token against the document, and they are all summed together to produce the final document score.

Baleen uses FLIPR, which stands for Focused Late Interaction Passage Retriever. Unlike ColBERT, FLIPR uses only the top-k highest scoring query tokens per document for scoring.
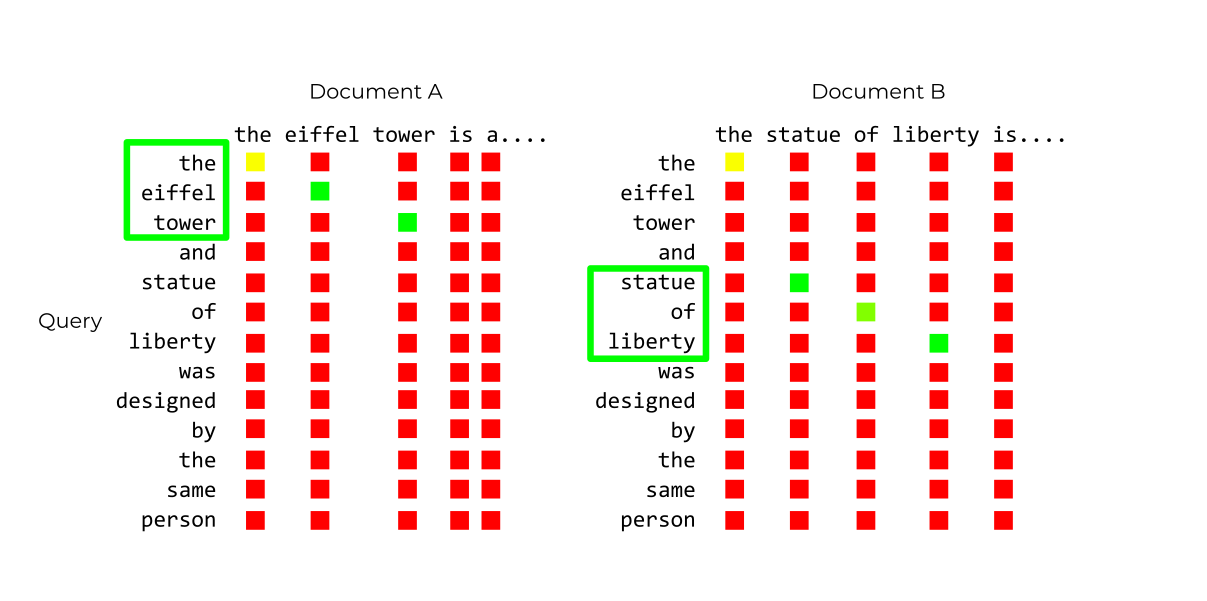
To see why this is helpful, consider the claim “The Statue of Liberty and the Eiffel Tower are located in the same country”. To verify this claim, Baleen would have to retrieve the Statue of Liberty and Eiffel Tower articles. Because ColBERT uses every query token, using standard ColBERT late interaction would likely retrieve the article for Gustav Eiffel, who contributed to both projects. By only using the highest scoring subset, several “sub-queries” can be generated from a single query.
In the figure below, we score a query against two different documents, using a k of 3. After finding the maximum
cosine similarity for each query token, only the top 3 tokens are used to compute the document’s score, indicated with a
green box. This allows both the article for the Eiffel Tower and Statue of Liberty to fulfill the provided query.
FLIPR computes the score contribution of the query separately from the contribution of the context. By default, 32 tokens from the query are used (half of the 64 tokens that form the query and padding), while only 8 tokens from the context are used.
To train FLIPR, the authors use latent hop ordering. Recall that HoVer gives us an unordered set of gold passage/sentence pairs. Some of these passage, however, can’t be retrieved based on information in the query alone. For example, in our “George Washington successor” example from before, the model wouldn’t be able to retrieve the article for “John Adams” before retrieving the article for “George Washington”, since it doesn’t know that John Adams succeeded George Washington yet. Since we modify the query, we also don’t actually know what queries will look like after the first hop. A big part of the challenge is to figure out not just which documents to retrieve, but when they should be retrieved.
Latent hop ordering extends the idea of weak supervison used in ColBERT-QA, the authors’ previous single-hop open domain question answering system. Generally speaking, weak interaction is a technique for labeling unlabled data using heuristics. This heuristic can take many forms, from using simple features that exploit biases in the data (such as using anchor text), to using existing models to estimate relevance.
In the single-hop task used in ColBERT-QA, gold passages are not provided, but a short answer string is, allowing for a retrieval heuristic based on BM25. During the first round of training, the authors use this BM25 heuristic to create positives and negatives, then train a ColBERT model based on these triples. The next two rounds of training then use the ColBERT model trained in the previous round. Effectively, after each round, you’re left with a model that can better determine passage relevance.
This brings us to the multi-hop setting. For the first hop, we use a ColBERT-QA model as our heuristic. Given the query, this retriever will want to retrieve certain gold passages before others. The highest ranked retrieved gold passages are treated as positives, while the non-gold passages are treated as negatives. We also produce a set of first-hop queries by adding gold fact sentences present in our first-hop gold passages to queries.
For the second hop, we finetune a standard ColBERT model trained on MS MARCO with the positives and negatives for the first hop, aand all remaining gold passages for the second hop, to produce a second-hop retriever. We can now use our second-hop retriever to produce positives and negatives with the same procedure we used for our first hop. This process continues until we have a set of positives and negatives for each hop we want to peform (usually 4), allowing us to train a model that works with every hop.
Condenser
After retrieving our initial set of documents, we have to figure out which facts are relevant. In order to scale to as many hops as possible, we want to retain the smallest number of facts that still allows us to answer the query. The condenser consists of two ELECTRA-based models, one which looks at whole passages to identify relevant facts, and another that looks at all relevant facts at once to perform even more filtering.
Stage 1
The stage 1 condenser looks at entire passages at once. Each sentence in the passage has a special token placed at the beginning (a [MASK] token, to be more precise). After passages are contextualized, the special tokens are run through a linear layer to produce relevance scores.
Using the per-hop positives and negatives we collected when training the retriever, the model is trained to output high scores for positive sentences, and low scores for negative sentences, using a cross-entropy loss. Note that we don’t use the gold sentences from our dataset yet; all sentences that come from a positive passage are considered positives.
Stage 2
After looking at all passages and scoring the sentences within, the top 9 fact sentences are sent to the second stage.
The stage 2 condenser looks at all of the facts at once. Like in the previous stage, each fact is prepended with a special token and scored. The loss used this time is a linear combination of binary cross entropy loss for each individual fact, and cross entropy loss for each positive fact against all negatives. This both incentivizes all positive facts to be scored higher than negatives and causes “better” positive facts to be scored higher.
All facts that have a positive score after this step are added to the context. If there are still hops left, this context is added to the query, creating the context for the next hop. Otherwise, the query and context are sent to the reader.
Reader
The reader is the final stage of Baleen, and frankly, the least interesting. The authors were focused on improving the retrieval aspect of multi-hop fact verification, so the reader is trained in the same way as prior approaches for a fair comparison. For claim verificiation, it outputs whether or not the claim was supported based on the query and retrieved facts. Like with the condensers, the reader is implemented with an ELECTRA model.
Conclusion
Baleen makes a number of interesting contributions to the field of multi-hop question answering:
- By using focused late interaction instead of full ColBERT interaction, documents only have to match against certain parts of the query and context, allowing different kinds of “queries” to be generated within a single hop.
- Latent hop ordering identifies which documents should be retrieved on which hop, mitigating the need to add hop labels to dataset items.
- Finally, the 2-stage condenser architecture reduces the multiple passages retrieved into a set of 1-4 sentences to be appended to the query, allowing the system to scale to multiple hops. Because of how condensing is done, facts are filtered based on both their context within a passage and their relationship to each other.
Given the number of tasks where at least one part can be described as “give me the most helpful documents for this query”, combined with its high performance, I’m thinking we’ll be seeing Baleen integrated into more systems in the future. I feel like one of the big obstacles at this point is that there are so many ideas in this paper to wrap your head around, you end up going with something else just for the simplicity. If that’s the case, hopefully this post helps!